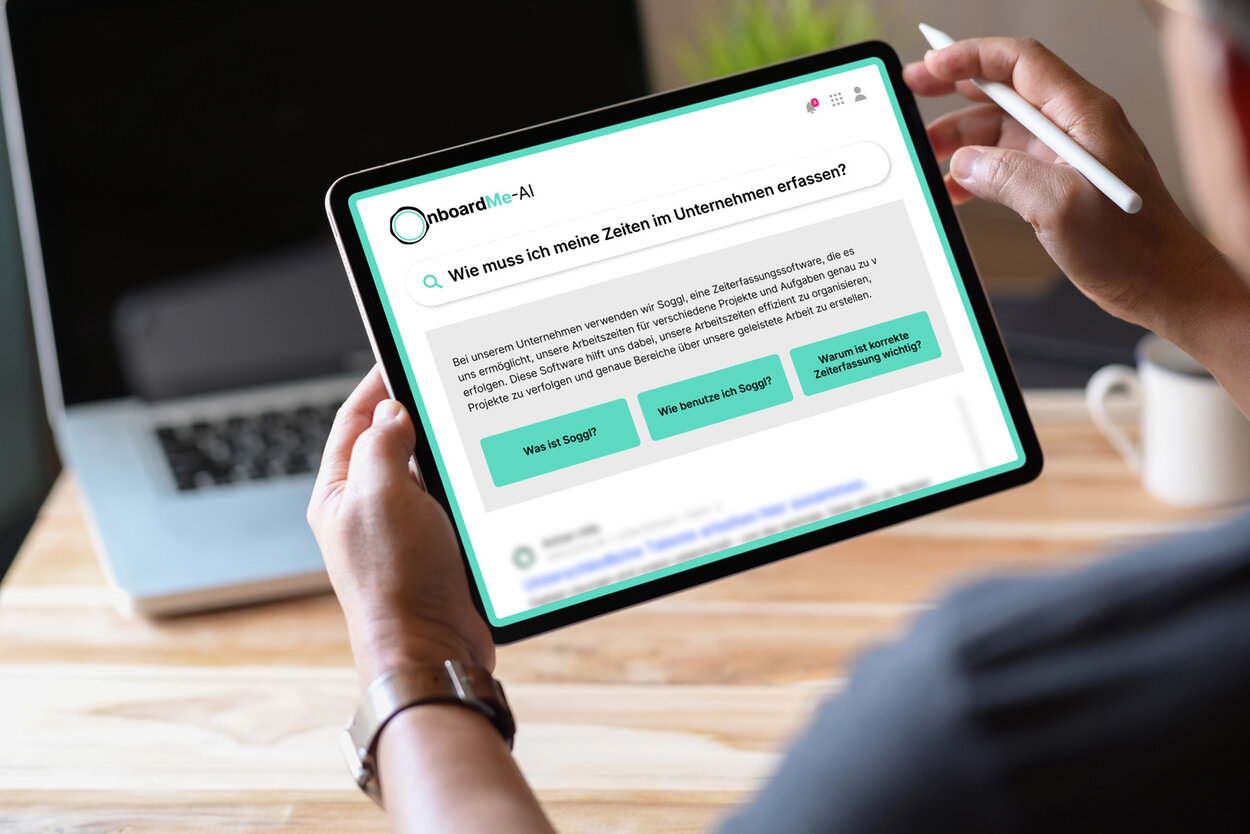
Niemand analysiert Millionen von Daten.
Unsere KI schon.
Niemand beherrscht alle Prozesse.
Unsere Software schon.
Niemand hat immer alles im Blick.
Unsere Managed Applications schon.
Noch nie waren die Voraussetzungen besser, um Unternehmen zu digitalisieren und mit digitalen Lösungen schnelle und tiefgreifende Verbesserungen zu erzielen. Lassen Sie uns die Chance gemeinsam nutzen. Wir machen Ihr Unternehmen mit Künstlicher Intelligenz, Software und dem Betrieb Ihrer Anwendungen schneller, leistungsstärker und resilienter.











Unternehmen digitalisieren. Wettbewerbsvorteile schaffen.
Alles ist und wird digital. Egal, in welcher Branche – Unternehmen müssen sich digitalisieren, um für die Zukunft gerüstet zu sein. Aber bedeutet "digital" auch automatisch "intelligent"? Nicht unbedingt. Intelligent ist es, ...
... Daten gewinnbringend zu nutzen.
... Datenflüsse zu beschleunigen.
... Anwendungen zu schützen.
... Künstliche Intelligenz einzusetzen.
Aber wie gelingt es, ein Unternehmen zu digitalisieren? Wir haben viele Kunden bei der Unternehmensdigitalisierung begleitet und mit digitalen Lösungen nachhaltige Wettbewerbsvorteile erzielt.
Künstliche Intelligenz
Daten gewinnbringend nutzen
Jedes Unternehmen sitzt auf einem riesigen Schatz – einer Unmenge an Daten, in denen Ihre Profitabilität von morgen steckt. Mit digitalen Lösungen – oder genauer: mit Künstlicher Intelligenz – schaffen wir es, diesen Rohstoff zu veredeln. Durch sichere Entscheidungen, ungeahnte Vereinfachungen und automatisierte Prozesse entlastet die KI Ihre Mitarbeitenden und befähigt sie.
Wir helfen Ihnen, Ihr Unternehmen zu digitalisieren und Ihre Unternehmensdaten sowie Ihre Mitarbeitenden so einzusetzen, dass es für Sie gewinnbringend ist.

Software
Datenflüsse beschleunigen
Software kann so viel mehr, wenn sie passgenau auf die spezifischen Bedürfnisse Ihres Unternehmens zugeschnitten ist. Erst dann entfaltet sie ihr ganzes Potenzial und beschleunigt Arbeitsprozesse.
Mit individueller Softwareentwicklung ergänzen wir Ihre Anwendungslandschaften, schaffen Schnittstellen und treiben die Digitalisierung von Geschäftsprozessen voran. Wir entwickeln Lösungen da, wo es noch keine gibt.

Managed Applications
Anwendungen schützen
Die IT-Systeme sind die wichtigsten Maschinen in jedem Unternehmen. Fallen sie aus oder sind Applikationen nicht verfügbar, leidet die Leistung des Unternehmens bis zum Stillstand.
Wenn wir Ihr Unternehmen digitalisieren, sorgen wir gleichzeitig dafür, dass Ihre Systeme rund um die Uhr laufen. Mit Managed Applications halten wir Ihre Anwendungen aktuell sowie performant und schützen sie vor Angriffen.

Forschung & Entwicklung
KI praktisch anwendbar machen
Wir forschen, um Unternehmen zu digitalisieren und Künstliche Intelligenz praktisch anwendbar zu machen. Dabei schaffen wir technische Grundlagen und lösen grundlegende Problemstellungen. Mit unserer Forschung sind wir nicht nur Teil der digitalen Zukunft – wir gestalten sie aktiv mit.

Karriere
IT-Place to be – hier findest du smarte Jobs!
Bei uns findest du ein Team, das deine Leidenschaft für Technologie und Software teilt. Bei uns kannst du dich ausprobieren und ständig weiterentwickeln. Schließ dich uns an. Gemeinsam unterstützen wir unsere Kunden dabei, ihre Unternehmen zu digitalisieren.

Unternehmen digitalisieren – mit LMIS
Wir kennen die aktuellen und zukünftigen Herausforderungen und eröffnen Unternehmen neue Horizonte. Mit Künstlicher Intelligenz, Software und Managed Applications schaffen wir es, Unternehmen zu digitalisieren. So verhelfen wir Ihnen zu mehr Schnelligkeit und effizienteren Prozessen und ermöglichen eine größere Resilienz und Sicherheit ihrer IT-Systeme.
Wir sorgen mit unseren individuellen Lösungen und umfassender Beratung dafür, dass Sie besser auf die Zukunft vorbereitet sind als Ihre Wettbewerber.
Unternehmen zu digitalisieren, ist nicht einfach. Mit LMIS schon. Wir verstehen unsere Kunden und stehen ihnen mit Rat und Tat zur Seite. Nehmen Sie jetzt Kontakt auf und überzeugen Sie sich selbst!